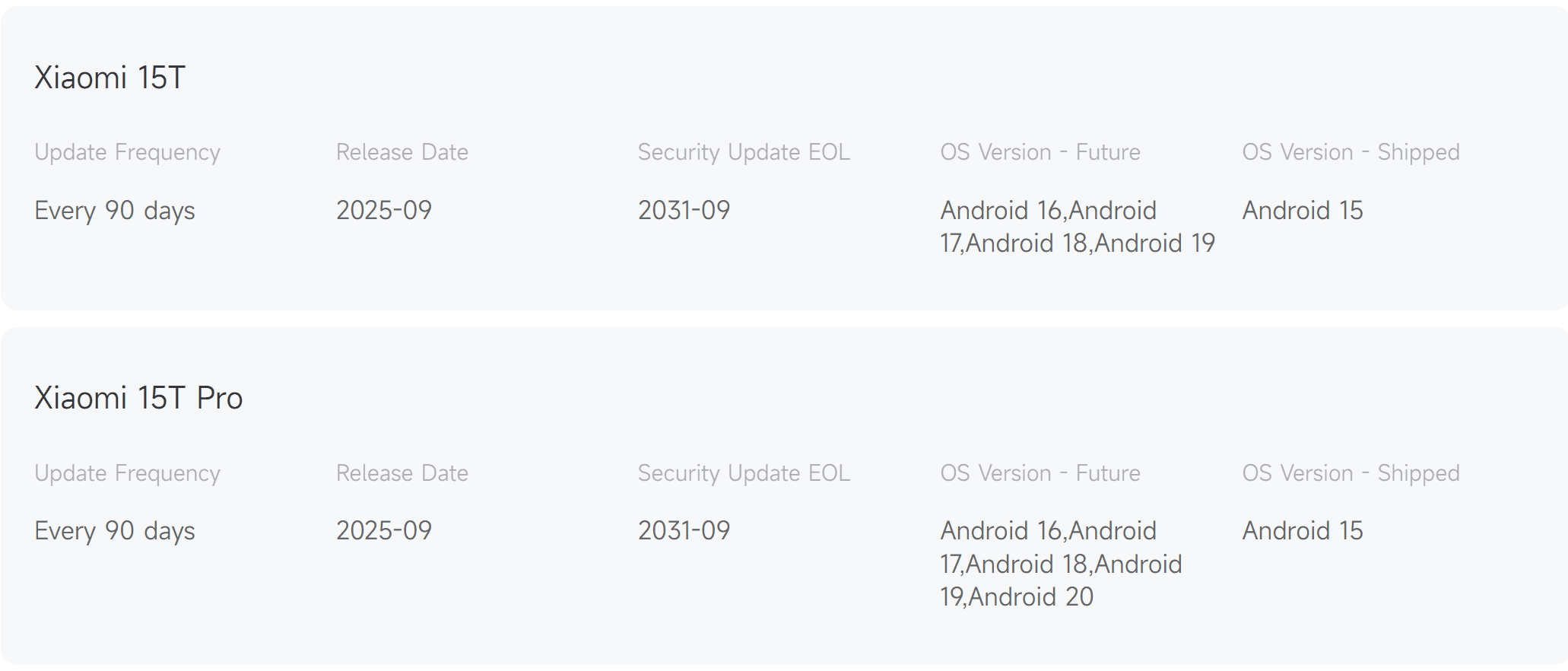




دیپسیک OCR امکان پردازش ۲۰۰ هزار صفحه مدارک را دارد

شرکت دیپسیک (DeepSeek) از یک مدل هوش مصنوعی متنباز جدید با نام DeepSeek OCR رونمایی کرده است که میتواند صنعت یادگیری ماشین را متحول کند.
به گزارش تکناک، این مدل قادر است روزانه بیش از ۲۰۰,۰۰۰ صفحه سند را تنها با استفاده از یک پردازنده گرافیکی انویدیا A100 پردازش و یاد بگیرد؛ دستاوردی که به لطف الگوریتمهای فشردهسازی و کدگذاری نوری پیشرفته آن ممکن شده است.
در دورانی که هزینههای سرسامآور مراکز داده هوش مصنوعی و پردازش داده به یک چالش اصلی برای شرکتهای فناوری تبدیل شده، تمرکز بر کارایی الگوریتمها اهمیت ویژهای یافته است. دیپسیک با ارائه مدلهای متنباز که هزینه آموزش بسیار کمتری نسبت به غولهایی مانند ChatGPT شرکت OpenAI یا Gemini شرکت گوگل دارند، در این زمینه پیشرو بوده است.
به نقل از نوتبوکچک، مدل DeepSeek-OCR با استفاده از یک تکنیک نوآورانه به نام «نگاشت نوری»، اسناد بسیار طولانی را به تصاویر فشرده تبدیل میکند. این سیستم میتواند بیش از ۹ توکن متنی را به یک توکن بصری واحد تبدیل کند که این امر منابع محاسباتی مورد نیاز برای پردازش محتوا را به شکل چشمگیری کاهش میدهد. این مدل حتی با نسبت فشردهسازی ۱۰ برابری، به دقت تشخیص ۹۷ درصدی دست مییابد و در نسبت فشردهسازی ۲۰ برابری نیز دقت ۶۰ درصدی را حفظ میکند که در نوع خود بیسابقه است.
این دستاورد در مقیاس بزرگتر شگفتانگیزتر میشود: یک خوشه محاسباتی متشکل از ۲۰ پردازنده A100 میتواند روزانه ۳۳ میلیون صفحه سند را پردازش کند. این یک تغییر پارادایم در نحوه آموزش مدلهای زبانی بزرگ مبتنی بر متن است. بر اساس رتبهبندی بنچمارک OmniDocBench، مدل DeepSeek-OCR رقبای محبوبی مانند GOT-OCR2.0 و MinerU2.0 را با اختلاف زیادی پشت سر میگذارد.

تواناییهای DeepSeek OCR به پردازش متون ساده محدود نمیشود. این مدل با تکیه بر معماری پیشرفته «ترکیب-متخصصان» (Mixture-of-Experts)، قادر است اسناد پیچیده حاوی نمودار، فرمولهای علمی، دیاگرام و تصاویر را حتی زمانی که به چندین زبان نوشته شده باشند، با دقت بالا پردازش کند. این موفقیت حاصل آموزش مدل بر روی مجموعه دادهای عظیم شامل ۳۰ میلیون صفحه PDF به نزدیک به ۱۰۰ زبان مختلف بوده است.
با وجود اینکه سرعت و کارایی سیستم جدید DeepSeek-OCR غیرقابل انکار است، یک پرسش کلیدی باقی میماند: آیا این کارایی فوقالعاده در پردازش و توکنسازی، در نهایت به بهبود عملکرد مدل زبانی در زمینه استدلال و درک واقعی مفاهیم نیز منجر خواهد شد؟ پاسخ به این سؤال، آینده این رویکرد نوآورانه را مشخص خواهد کرد.
نوشته دیپسیک OCR امکان پردازش ۲۰۰ هزار صفحه مدارک را دارد اولین بار در Technoc. پدیدار شد.
واکنش شما چیست؟
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0