











مدل زبان بزرگ LLaVA-o1 چینی برای رقابت با OpenAI معرفی شد
محققان چینی مدل زبانی بزرگ LLaVA-o1 را معرفی کردهاند که به عنوان رقیب مدل o1 شرکت OpenAI مطرح شده است. به گزارش تکناک، این مدل جدید با هدف بهبود تواناییهای استدلال و حل مسئله در مدلهای زبانی بزرگ طراحی شده است و تلاش میکند تا در آزمونهای پیچیده مانند المپیاد ریاضی بینالمللی عملکرد بهتری نسبت […] نوشته مدل زبان بزرگ LLaVA-o1 چینی برای رقابت با OpenAI معرفی شد اولین بار در تک ناک. پدیدار شد.

محققان چینی مدل زبانی بزرگ LLaVA-o1 را معرفی کردهاند که به عنوان رقیب مدل o1 شرکت OpenAI مطرح شده است.
به گزارش تکناک، این مدل جدید با هدف بهبود تواناییهای استدلال و حل مسئله در مدلهای زبانی بزرگ طراحی شده است و تلاش میکند تا در آزمونهای پیچیده مانند المپیاد ریاضی بینالمللی عملکرد بهتری نسبت به مدلهای قبل از خود نشان دهد.
ونچربیت مینویسد که مدل o1 شرکت OpenAI پیشتر نشان داده بود که افزایش قدرت محاسباتی در زمان استنتاج میتواند تواناییهای استدلالی مدلهای زبانی را به طور قابل توجهی بهبود بخشد. اکنون پژوهشگران چینی این ایده را در مدل زبان بزرگ LLaVA-o1 پیادهسازی کردهاند تا استدلال منطقی و ساختاریافته در مدلهای متنباز را ارتقا دهند.
مشکلات مدلهای تصویری متنباز
مدلهای تصویری متنباز اولیه، اغلب با استفاده از روش پیشبینی مستقیم، پاسخهایی تولید میکردند که فاقد استدلال درباره پرسش یا مراحل مورد نیاز برای حل آن بودند.
این ضعف باعث میشد که این مدلها در وظایفی که نیاز به استدلال منطقی دارند، عملکرد ضعیفی داشته باشند.
تکنیکهای پیشرفتهتر مانند Chain-of-Thought (CoT) که مدلها را به تولید مراحل میانی استدلال تشویق میکنند، تنها بهبودهای جزئی ایجاد کردند.
پژوهشگران چینی مشاهده کردند که یکی از مشکلات اصلی این مدلها، نبود فرایند استدلال سیستماتیک و ساختاریافته است.
مدلهای موجود نمیتوانند زنجیرههای منطقی استدلالی ایجاد کنند و اغلب در مسیری گیر میکنند، که مشخص نیست در کدام مرحله قرار دارند و چه مشکلی را باید حل کنند.
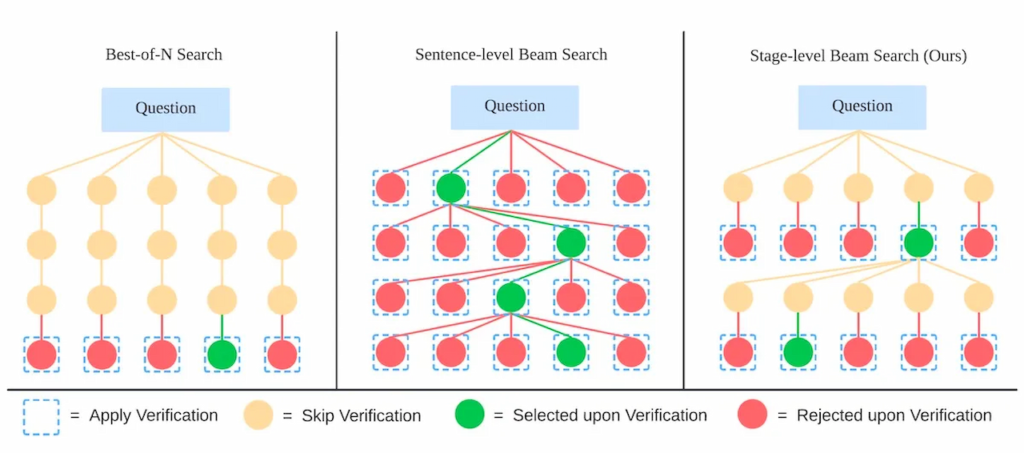
رویکرد مدل زبان بزرگ LLaVA-o1 برای استدلال مرحلهای
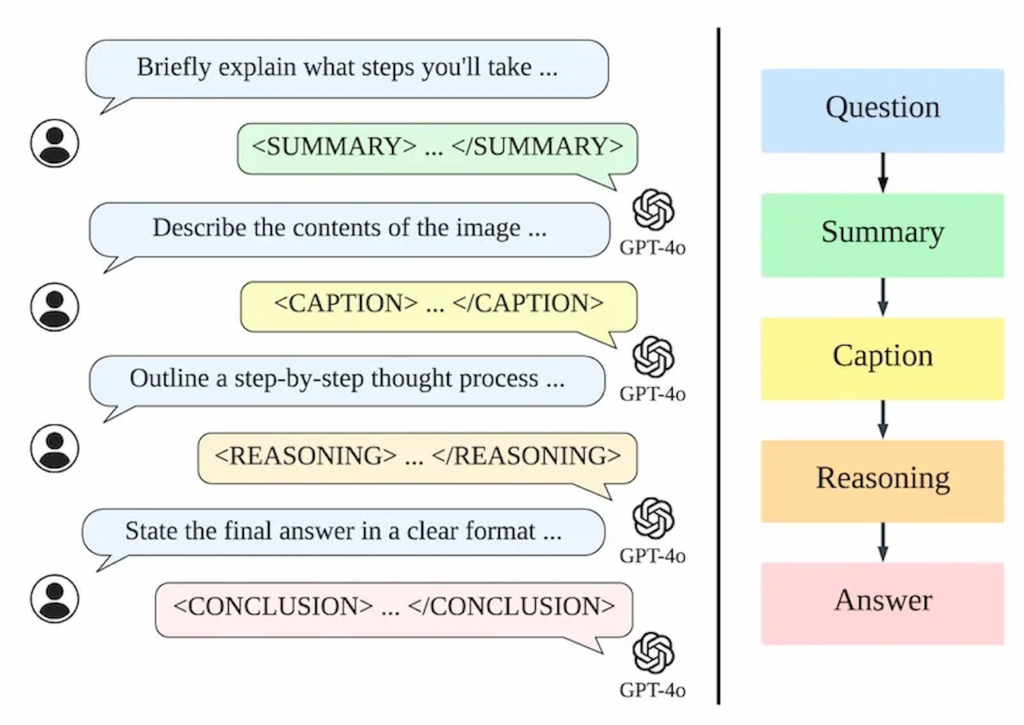
پژوهشگران برای حل این مشکلات، مدل LLaVA-o1 را به گونهای طراحی کردند که فرایند استدلال را به چهار مرحله مجزا تقسیم کند:
- خلاصهسازی: مدل ابتدا خلاصهای کلی از پرسش ارائه میدهد و مشکل اصلی را مشخص میکند.
- توصیف تصویر: اگر تصویری وجود داشته باشد، مدل بخشهای مرتبط با پرسش را توصیف میکند.
- استدلال: با تکیه بر خلاصهسازی، مدل استدلالی منطقی و ساختاریافته انجام میدهد تا به پاسخ اولیه دست یابد.
- نتیجهگیری: در نهایت، مدل خلاصهای نهایی از پاسخ را ارائه میکند.
در این رویکرد، تنها مرحله «نتیجهگیری» برای کاربر قابل مشاهده است و سه مرحله دیگر فرایند داخلی مدل را تشکیل میدهند. این ساختار باعث میشود که مدل بتواند فرایند استدلال خود را به صورت مستقل مدیریت کند و عملکرد آن در وظایف پیچیده بهبود یابد.
علاوه بر این، مدل زبان بزرگ LLaVA-o1 از تکنیک جدیدی به نام جستوجوی پرتوی مرحلهای استفاده میکند، که در هر مرحله چندین پاسخ کاندید تولید و بهترین گزینه را برای ادامه انتخاب میکند.
این رویکرد برخلاف روشهای کلاسیک، امکان بررسی دقیقتر و کارآمدتر را در هر مرحله فراهم میکند.
عملکرد و نتایج مدل زبان بزرگ LLaVA-o1
پژوهشگران برای آموزش LLaVA-o1، یک مجموعه داده جدید شامل حدود ۱۰۰ هزار جفت سؤال-پاسخ تصویری ایجاد کردند، که از چندین مجموعه داده مشهور VQA گردآوری شده است.
این مجموعه داده شامل وظایفی همچون پرسش و پاسخ چندمرحلهای، تفسیر نمودارها و استدلالهای هندسی بود.
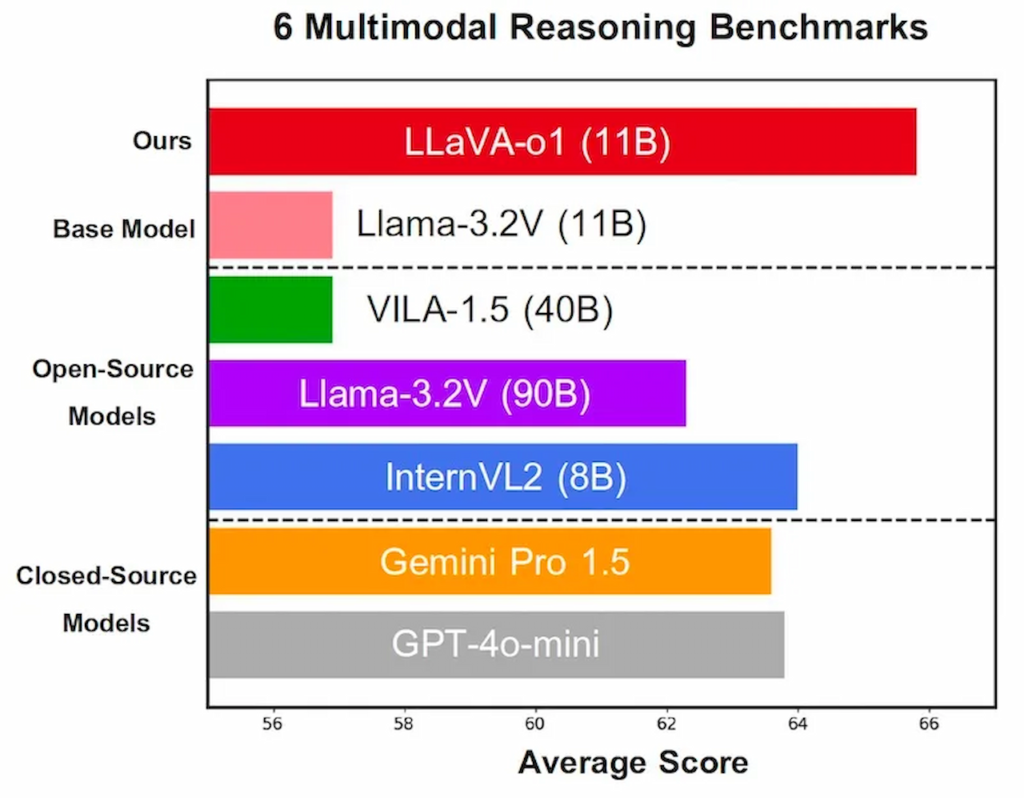
مدل LLaVA-o1 با وجود آموزش روی تنها ۱۰۰ هزار نمونه، عملکرد قابل توجهی در چندین معیار استدلال چندرسانهای نشان داد و امتیاز معیارها را به طور متوسط ۶.۹ درصد افزایش داد.
علاوه بر این، استفاده از تکنیک جستوجوی پرتوی مرحلهای نیز باعث بهبود عملکرد مدل شد.
پژوهشگران با توجه به محدودیت منابع محاسباتی، این روش را تنها با اندازه پرتو ۲ آزمایش کردند و معتقد هستند که با افزایش اندازه پرتو، بهبودهای بیشتری حاصل خواهد شد.
نکته قابل توجه این است که مدل زبان بزرگ LLaVA-o1 نه تنها از سایر مدلهای متنباز هماندازه یا بزرگتر پیشی گرفت، بلکه توانست عملکردی بهتر از برخی مدلهای بسته مانند GPT-4-o-mini و Gemini 1.5 Pro ارائه دهد.
گام بعدی در استدلال چندرسانهای
پژوهشگران در گزارش خود نوشتند: «مدل زبان بزرگ LLaVA-o1 استاندارد جدیدی برای استدلال چندرسانهای در مدلهای تصویری ارائه میدهد و عملکرد و مقیاسپذیری قوی به ویژه در زمان استنتاج ارائه میکند. این پژوهش، مسیر را برای تحقیقات آینده در زمینه استدلال ساختاریافته در مدلهای تصویری، از جمله استفاده از تأییدکنندگان خارجی و بهرهگیری از یادگیری تقویتی برای بهبود تواناییهای استدلالی پیچیده، باز مینماید.»
اگرچه مدل LLaVA-o1 هنوز به صورت عمومی منتشر نشده است، اما پژوهشگران اعلام کردهاند که مجموعه داده مورد استفاده در آموزش این مدل، با نام LLaVA-o1-100k، به زودی در دسترس قرار خواهد گرفت.
نوشته مدل زبان بزرگ LLaVA-o1 چینی برای رقابت با OpenAI معرفی شد اولین بار در تک ناک. پدیدار شد.
واکنش شما چیست؟