




























رونمایی OpenAI از مدلهای صوتی نسل جدید
شرکت OpenAI از مدلهای صوتی نسل جدید خود برای بهبود عملکرد دستیارهای صوتی هوشمند رونمایی کرد. این مدلها قابلیت تبدیل متن به گفتار (TTS) و پردازش صوتی پیشرفته را ارائه میدهند و دقت، کیفیت و تعامل طبیعیتر در مکالمات را بهبود میبخشند. به گزارش تکناک، این مدلها از طریق API در اختیار توسعهدهندگان قرار گرفتهاند […] نوشته رونمایی OpenAI از مدلهای صوتی نسل جدید اولین بار در تک ناک - اخبار تکنولوژی روز جهان و ایران. پدیدار شد.
شرکت OpenAI از مدلهای صوتی نسل جدید خود برای بهبود عملکرد دستیارهای صوتی هوشمند رونمایی کرد. این مدلها قابلیت تبدیل متن به گفتار (TTS) و پردازش صوتی پیشرفته را ارائه میدهند و دقت، کیفیت و تعامل طبیعیتر در مکالمات را بهبود میبخشند.
به گزارش تکناک، این مدلها از طریق API در اختیار توسعهدهندگان قرار گرفتهاند و به گفته OpenAI، نسبت به مدلهای قبلی از دقت، انعطافپذیری و قابلیت شخصیسازی بالاتری برخوردارند.
نئووین مینویسد که این شرکت در ماههای گذشته ابزارهای متعددی نظیر Operator، Deep Research، Computer-Using Agents و Responses API را معرفی کرده بود که همگی بر عاملهای متنی تمرکز داشتند. اما اکنون با ارائه مدلهای صوتی gpt-4o-transcribe و gpt-4o-mini-transcribe، OpenAI گام بلندی به سوی توسعه عاملهای صوتی برداشته است.
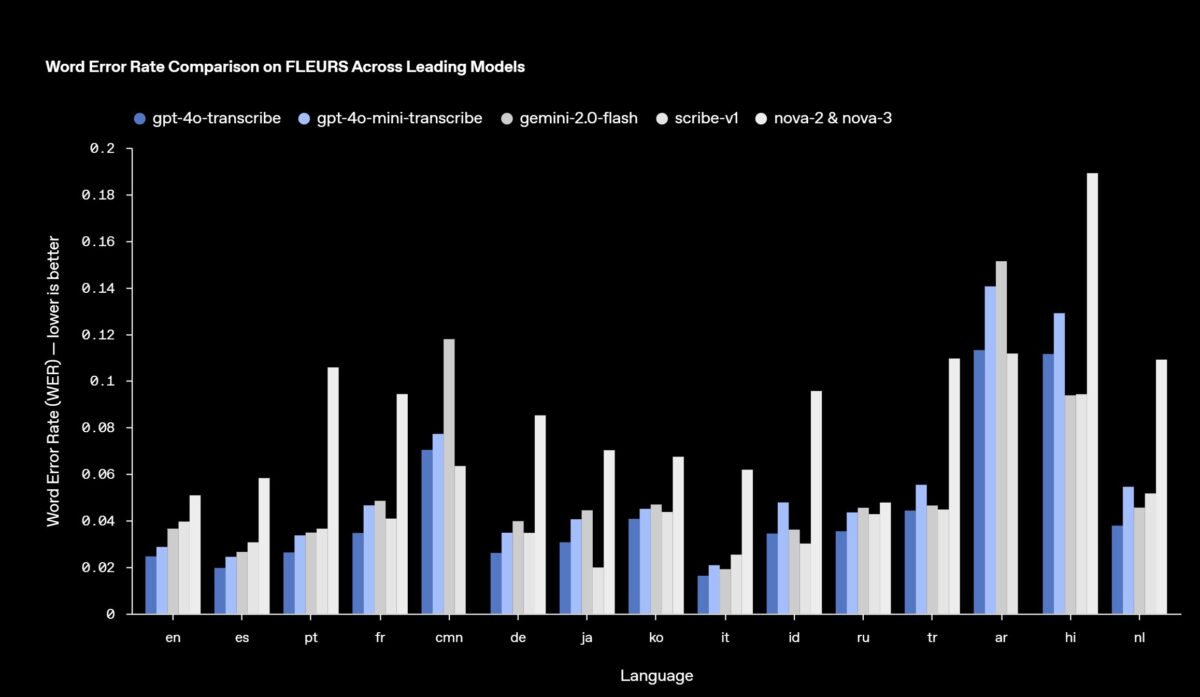
بهگفته OpenAI، این مدلهای گفتار به متن در مقایسه با نسل قبلی یعنی Whisper، نرخ خطای واژگانی کمتری دارند و عملکرد بهتری در تشخیص زبان و دقت کلی ارائه میدهند. این بهبودها نتیجه استفاده از یادگیری تقویتی و آموزشهای گسترده مبتنی بر دادههای صوتی متنوع و با کیفیت بالا بوده است. همچنین این مدلها قادرند تفاوتهای ظریف در گفتار را بهتر درک کنند، موارد شناسایی نادرست را کاهش دهند و حتی در شرایطی مانند لهجههای گوناگون، محیطهای پر سر و صدا و سرعتهای مختلف صحبت، دقت تبدیل را حفظ کنند.
علاوه بر این، مدل gpt-4o-mini-tts بهعنوان جدیدترین مدل تبدیل متن به گفتار معرفی شده که توانایی هدایتپذیری بالاتری دارد. توسعهدهندگان اکنون میتوانند شیوه بیان متن را بهطور مستقیم به مدل اعلام کنند. هرچند فعلاً این مدل فقط از صداهای مصنوعی از پیش تعیینشده پشتیبانی میکند.
هزینه استفاده از مدلهای جدید نیز بهصورت دقیق اعلام شده است. برای gpt-4o-transcribe، هزینه هر یک میلیون توکن ورودی صوتی ۶ دلار، توکن متنی ورودی ۲.۵ دلار و توکن متنی خروجی ۱۰ دلار تعیین شده است. مدل gpt-4o-mini-transcribe با هزینههای ۳ دلار، ۱.۲۵ دلار و ۵ دلار برای همان سطوح ارائه میشود. همچنین استفاده از مدل gpt-4o-mini-tts برای هر یک میلیون توکن متنی ورودی ۰.۶ دلار و برای هر یک میلیون توکن صوتی خروجی ۱۲ دلار هزینه دارد. بر این اساس، هزینه استفاده در هر دقیقه بهطور تقریبی به شرح زیر است:
- gpt-4o-transcribe: حدود ۰.۶ سنت
- gpt-4o-mini-transcribe: حدود ۰.۳ سنت
- gpt-4o-mini-tts: حدود ۱.۵ سنت
تیم شرکت OpenAI در بیانیهای رسمی اعلام کرد: «در آینده، قصد داریم سرمایهگذاری برای افزایش هوشمندی و دقت مدلهای صوتی را ادامه دهیم و امکان استفاده از صداهای سفارشی توسط توسعهدهندگان را فراهم کنیم تا بتوانند تجربههایی شخصیسازیشده و منطبق با استانداردهای ایمنی ما ارائه دهند.»
این مدلهای صوتی اکنون برای تمامی توسعهدهندگان از طریق API در دسترس قرار گرفتهاند. همچنین OpenAI از یکپارچهسازی این مدلها با Agents SDK خبر داده که فرآیند توسعه دستیارهای صوتی را تسهیل میکند. برای ساخت تجربههای گفتار به گفتار با تأخیر پایین نیز استفاده از Realtime API پیشنهاد شده است.
نوشته رونمایی OpenAI از مدلهای صوتی نسل جدید اولین بار در تک ناک - اخبار تکنولوژی روز جهان و ایران. پدیدار شد.
واکنش شما چیست؟














